%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Image Description

Describe Anything
The Describe Anything model (DAM) can process specific regions of images or videos and generate detailed descriptions. Its main advantage lies in its ability to generate high-quality localized descriptions through simple markings (points, boxes, scribbles, or masks), greatly enhancing image understanding capabilities in the field of computer vision. The model was jointly developed by NVIDIA and several universities and is suitable for research, development, and practical applications.
Image Generation
40.6K
MILS
MILS is an open-source project released by Facebook Research, designed to demonstrate the capabilities of large language models (LLMs) in handling visual and auditory tasks without any prior training. This technology leverages pre-trained models and optimization algorithms to automatically generate descriptions for images, audio, and video. This breakthrough offers new insights into the development of multi-modal AI, showcasing the potential of LLMs in cross-modal tasks. The model is primarily targeted at researchers and developers, providing them with a powerful tool to explore multi-modal applications. Currently, this project is free and open-source, aimed at advancing academic research and technological development.
AI Model
47.5K
Smolvlm 500M Instruct
SmolVLM-500M, developed by Hugging Face, is a lightweight multimodal model that belongs to the SmolVLM series. Based on the Idefics3 architecture, it focuses on efficient image and text processing tasks. The model can accept image and text inputs in any order and generate text outputs, making it suitable for tasks such as image description and visual question answering. Its lightweight design allows it to operate on resource-constrained devices while maintaining strong performance in multimodal tasks. The model is licensed under the Apache 2.0 license, enabling open-source and flexible usage scenarios.
AI Model
59.6K
Paligemma2 3b Pt 224
Developed by Google, PaliGemma 2 is a vision-language model that combines the capabilities of the SigLIP visual model and the Gemma 2 language model. It is capable of processing both image and text inputs to generate corresponding text outputs. This model excels in various vision-language tasks such as image description and visual question answering. Its main advantages include robust multilingual support, an efficient training architecture, and outstanding performance across diverse tasks. PaliGemma 2 was developed to tackle complex interactions between vision and language, aiding researchers and developers in achieving breakthroughs in their respective fields.
AI Model
45.8K
Paligemma2 3b Pt 448
PaliGemma 2 is a vision-language model developed by Google, inheriting the capabilities of the Gemma 2 model, enabling it to handle image and text inputs to generate text outputs. The model excels in various visual language tasks such as image description and visual question answering. Its main advantages include robust multilingual support, an efficient training architecture, and extensive applicability. This model is suitable for a wide range of applications that require processing visual and textual data, such as social media content generation and intelligent customer service.
AI Model
43.1K
Smart Image Description Generator
The Smart Image Description Generator is an AI-driven online tool that automatically creates accurate, context-sensitive descriptive text for website images, enhancing search engine rankings and improving website SEO and accessibility. It supports over 20 languages and employs cutting-edge AI technology to generate natural, SEO-optimized descriptions that help users increase their image click-through rates, gain more organic traffic, and enhance website visibility.
AI design tools
63.2K
Picwordify
PicWordify is a product that leverages AI technology to automatically generate accurate descriptive text (alt text) for images on websites. It supports over 130 languages, enhancing website accessibility and boosting SEO effectiveness. Through simple code integration, users can quickly add descriptions to both new and existing images, thereby improving search engine rankings and increasing image search traffic. Background information indicates that PicWordify has processed over 5 million images with an accuracy rate of 99.9%, making it a powerful tool for enhancing website SEO and accessibility. In terms of pricing, PicWordify offers both a free plan and paid plans, allowing users to choose the service that best meets their needs.
SEO optimization
51.1K
Joy Caption Batch
joy-caption-batch is a programming model that uses the Joytag Caption tool to batch generate descriptive titles for image files. Currently in the Alpha stage, it analyzes image content to generate corresponding text descriptions using artificial intelligence, helping users quickly understand the content of their images. Key advantages of this tool include batch processing capability, support for custom image directories, and LOW_VRAM_MODE support, allowing it to run on devices with low memory. Additionally, detailed installation and usage instructions are provided to help users get started quickly.
Image Generation
57.1K
AI Describe Pictures
AI Describe Pictures is a platform built using advanced AI models that can quickly generate detailed or brief descriptions for images. Utilizing AI technology, it not only describes the scenes and characters within images but also provides customizable description options according to user needs. This product, by leveraging AI tech, significantly improves the efficiency and accuracy of image descriptions, making it particularly valuable for individuals with visual impairments, content creators, and various scenarios requiring image descriptions.
Image Generation
65.4K
Chinese Picks
Describepic
Leverages AI technology to describe uploaded images, assisting users in quickly generating image explanations. Suitable for content creators and social media users, it enhances the readability and appeal of image content.
Image Generation
152.9K
Florence 2 Large
Florence-2-large, developed by Microsoft, is an advanced vision foundation model that uses a prompt-based approach to handle a wide range of visual and visual-language tasks. The model can interpret simple text prompts to perform tasks such as image description, object detection, and segmentation. It is trained on the FLD-5B dataset, which contains 540 million images with 5.4 billion annotations, making it proficient in multi-task learning. Its sequence-to-sequence architecture enables it to perform well in both zero-shot and fine-tuning settings, proving to be a competitive vision foundation model.
AI image generation
57.1K
Idefics 80b
HuggingFaceM4/idefics-80b-instruct is an open-source multimodal model that can accept both image and text input and generate relevant text output. It excels in tasks like visual question answering and image description, making it a versatile intelligent assistant model. Developed by the Hugging Face team, it's trained on open datasets and is available for free use.
AI Model
63.5K
AI Describe Picture
AI Describe Picture is a revolutionary platform that leverages artificial intelligence to provide rich contextual descriptions for your images. With intuitive upload, interactive chat, and social sharing features, it brings an unprecedented image exploration experience. Step into the new era of AI-driven image description.
Image Generation
77.8K

Genalt Generate AI Alternate Text
GenAlt generates descriptive alternative text for online images, providing assistance to those who need it. Simply right-click on an image and click "Get Alt Text from GenAlt" to obtain a description of the image as its alt text. To view the generated caption and copy it to your clipboard, simply select "Copy AI Image Description from GenAlt". Here are some user testimonials for GenAlt:
1. "GenAlt has been incredibly helpful for me in understanding photos... much better than existing tools." – Accessibility advocate and Twitch streamer
2. "GenAlt is really more helpful than other apps I've found on the internet, really helping me describe pictures better." – High School sophomore Remi
3. "GenAlt is easy to use and helps make social media more accessible to me." – College freshman Aaron
AI image detection and recognition
52.7K
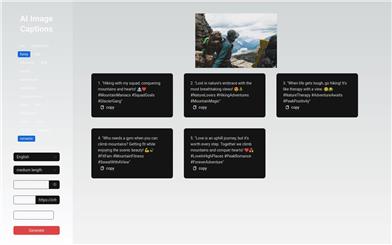
AI Image Captions
AI Image Captions is an AI-powered smart image caption generation tool. It can automatically analyze image content and generate multiple style text descriptions related to the image theme, including humorous, formal, and sales-oriented styles. Users only need to upload an image to get multiple intelligently generated image text descriptions. This product is feature-rich, easy to use, and can greatly improve the efficiency of image text description generation. It is a powerful tool for writers, designers, product managers, and other professionals.
Image Editing
64.9K
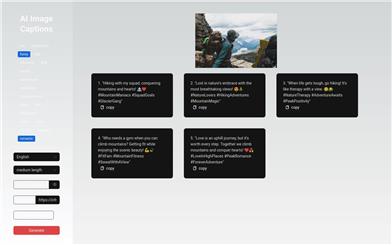
Felix Link Captions
Felix Link Captions aims to provide users with image descriptions in various styles, including humorous, lighthearted, and witty. Users can choose descriptions based on their needs, ranging from funny to romantic, professional, and playful. The product offers flexible pricing and focuses on providing personalized image description services.
Document Generator
46.1K
SEED
SEED is a large-scale pre-trained model that, through pre-training and guided fine-tuning on interwoven text and visual data, demonstrates outstanding performance in a wide range of multi-modal understanding and generation tasks. SEED also possesses emerging combinatorial capabilities, such as multi-turn contextual multi-modal generation, much like your AI assistant. SEED also includes SEED Tokenizer v1 and SEED Tokenizer v2, which can convert text into images.
AI Model
58.5K

Genalt Generated AI Image Descriptions
GenAlt uses artificial intelligence to generate descriptive alt text for online images that lack descriptions! Simply right-click on an image, click GenAlt to get the image description, and you'll have a description of the image as its alt text. Please note: GenAlt will display as a brief pop-up window of the title generated for the image.
AI image detection and recognition
45.5K

ALT AI: Add Alt Text To Image Descriptions
ALT AI: Adding Alt text to image descriptions is an accessibility tool that adds alt text to any webpage on the internet. ALT AI aims to improve the web experience for visually impaired users. Using the ALT AI Chrome extension, you can automatically add alt text to every image on a page, replacing any inaccurate existing alt descriptions. Screen readers will read aloud the ALT AI generated alt text, helping users better understand the content on the page.
AI image detection and recognition
56.6K

Minigpt 4
MiniGPT-4 is a visual language understanding model based on advanced large language models, capable of generating detailed image descriptions, creating websites from handwritten sketches, and more. It can also write stories and poems based on given images, provide solutions to problems, and even teach users how to cook based on food photographs. MiniGPT-4 is pre-trained on raw image-text pairs and fine-tuned using dialogue templates and aligned data to improve the coherence and accuracy of its generated outputs. For pricing and other details, please refer to the official website.
AI image generation
45.0K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.2K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.0K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.7K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.2K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M